1000行代码写出世界第一的网页Agent?微软Webwright的工程哲学
微软开源了 Webwright,一个仅 1000 行代码的网页 Agent 框架。它在长链路任务上超越 Opus 4.6 达 35%。核心不在模型,而在两个精巧的工程设计:门控自检和历史压缩。
1000 行代码写出世界第一的网页 Agent?
微软研究院最近做了一个很反直觉的事。
他们开源了一个网页智能体框架叫 Webwright,能让 AI 模型像人类开发者一样操控浏览器——填写表单、跨页面操作、完成多步骤任务。听起来很复杂对吧?但这个框架总代码量只有 1000 行。
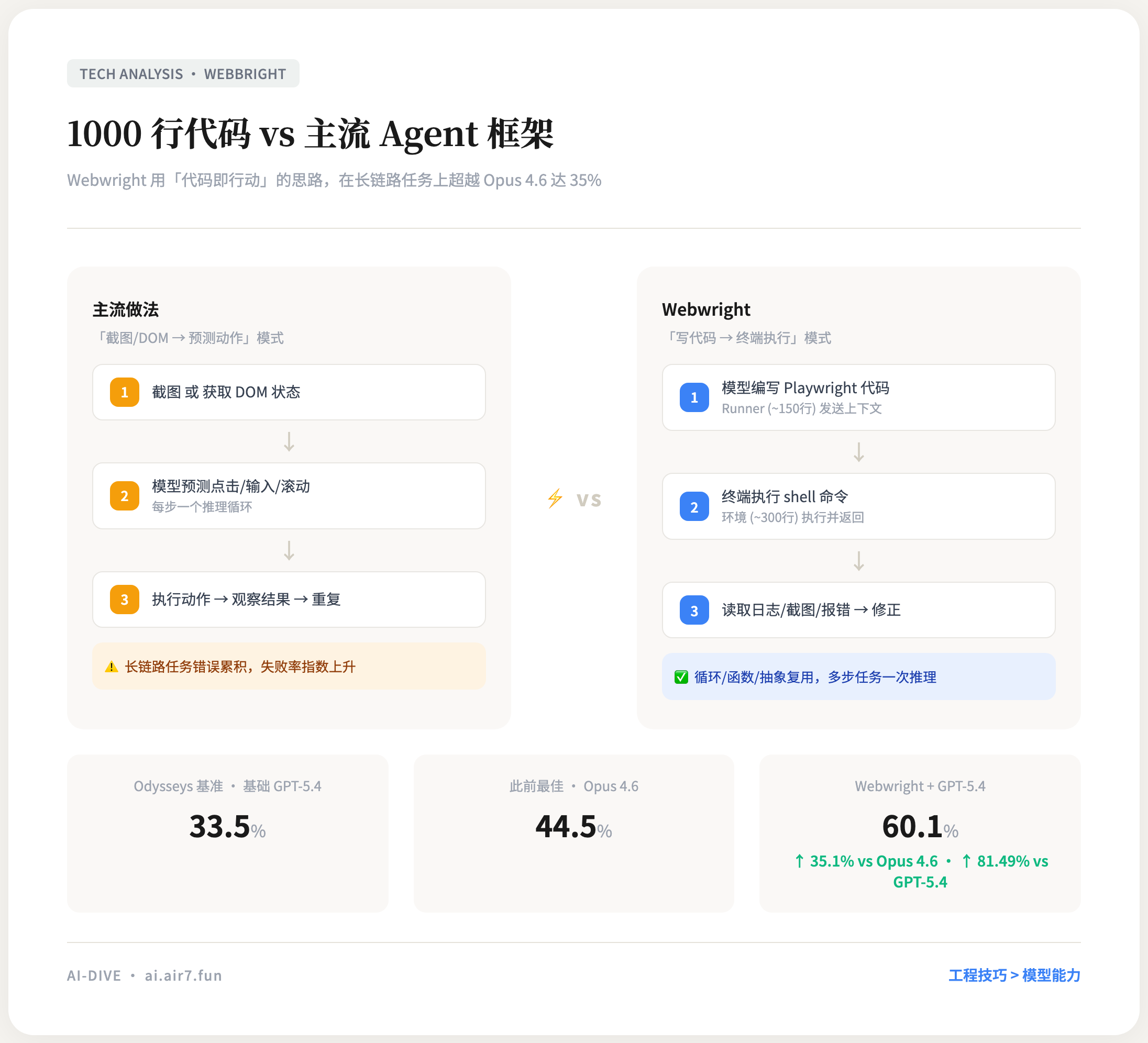
没错,1000 行。Runner 约 150 行,模型接口约 550 行,环境部分约 300 行。没有多智能体编排,没有复杂的分层规划,没有花哨的包装。
而它在长链路网页浏览基准测试 Odysseys 上的得分,比之前最好的模型(Opus 4.6,44.5%)高出 35%,达到 60.1%。对比基础 GPT-5.4 的 33.5%,提升了 81.49%。
代码量和效果的反差,揭示了一个正在形成的共识:在 Agent 领域,工程技巧比模型能力更重要。
为什么是代码,而不是"预测点击"
主流的网页 Agent 走的是"截图或 DOM 状态 → 预测下一次点击、输入、滚动"的路线。模型被训练成预测一个低级动作——比如"点击坐标(450, 320)"或"在输入框@id=search 中输入'hello'"。
问题在于,大多数有实际价值的网页任务都不是一个动作能完成的。填写一个表单需要:定位输入框 → 输入 → 选择日期 → 点击提交 → 验证结果。跨页面操作需要:点击链接 → 等待加载 → 提取信息 → 返回上一页 → 填入另一处。
用"预测下一个低级动作"的方式做这件事,每一步都需要模型判断,每步都有出错的可能。错误的累积效应会让长链路任务的失败率指数级上升。
Webwright 的思路完全不同:让模型直接写 Playwright 代码,然后在终端里执行。
代码比动作指令强大在哪里?一个 for 循环可以遍历 10 个页面元素,一个 if 条件可以处理不同情况,一个函数可以把 3 步操作打包成一个抽象。模型不需要预测每一步该做什么,只需要写出一个正确的脚本,然后让脚本执行。
这就是"代码即行动"(Code as Actions)的思路。Webwright 的论文标题直接叫 "A Terminal Is All You Need For Web Agents"——一台终端就够了。
这听起来像是退回了老路,但实际上是重新认识了什么才是表达复杂行为最自然的语言。
两个工程问题,两个精巧解法
整个框架的核心价值不在架构设计——架构层只有三个组件(Runner、Model Endpoint、终端环境)——而在两个具体工程问题的解法上。
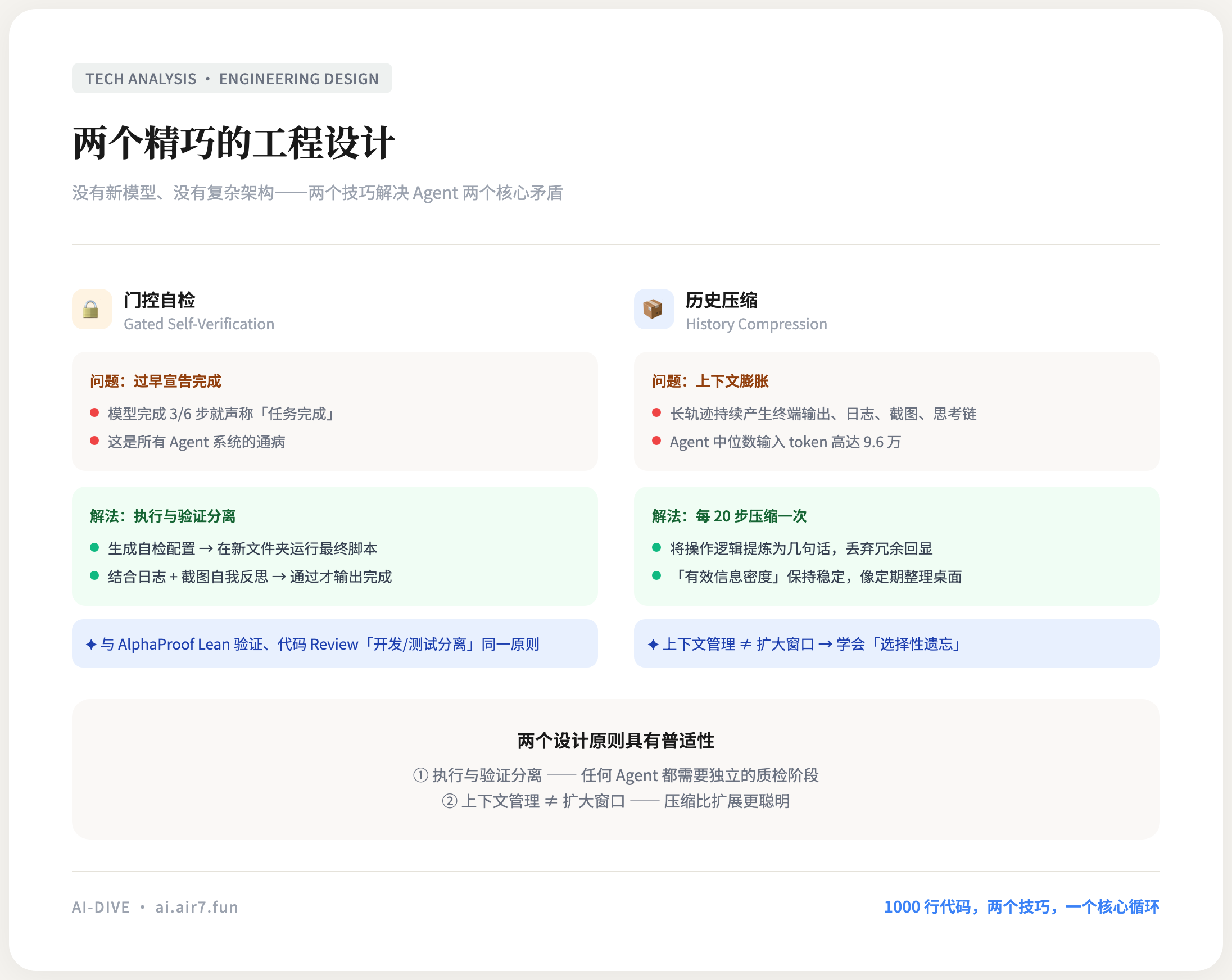
第一个问题是"过早宣告完成"。
这是所有 Agent 系统的通病。模型在某个时刻觉得"我好像完成了"然后就停下来了。有时候它确实完成了,但大多数时候它只是忽略了自己漏掉的步骤。在一个长链路任务中,模型可能只完成了 6 步中的 3 步,却自信地报告"任务完成"。
Webwright 的解法很巧妙:门控自检(Gated Self-Verification)。模型不能直接说"我完成了"。它必须先生成一个自检配置——描述如何验证任务是否成功——然后在一个全新的、干净的文件夹里运行最终脚本。运行完成后,结合终端日志和截图,通过自我反思来判断这个结果是否真的正确。
这个门控步骤的意义在于,它迫使模型把"完成任务"和"验证完成"两个过程分开。后者需要更严谨的推理,因为它面对的是自己刚刚产出的结果。人做代码 Review 也是类似——写代码的人和判断代码是否通过的人,应该是两个不同的思维状态。
第二个问题是上下文膨胀。
长轨迹的网页操作会持续产生终端输出、日志、截图描述、模型思考链。几十步下来,上下文可能轻松超过 10 万 token,即使是最新的 150 万 token 模型也会被不相关的历史淹没。
Webwright 的做法是每 20 步把历史压缩成一份摘要。不是简单截断,而是让模型把之前的操作逻辑提炼成几句话——"访问了 X 页面,在 Y 输入框中填写了 Z,点击提交后收到了 W 响应"。摘要保留了语义关键信息,去掉了冗余的终端回显和调试输出。
这个压缩策略很关键。Agent 上下文不会无限增长,但它的"有效信息密度"会在摘要后保持稳定。每 20 步一次的刷新,相当于让 Agent 定期"整理桌面"。
两个设计原则的普适性
门控自检和历史压缩,看起来是 Webwright 的两个特制技巧,但它们反映的是更通用的 Agent 设计原则。
原则一:执行与验证分离。 当 Agent 既负责做事又负责检查时,它会倾向于对自己的工作过于乐观。这和人类写代码时的"开发者和测试者不能是同一个人"是同一个道理。任何严肃的 Agent 系统都应该有一个独立的验证阶段,强制 Agent 站在批判者的角度审视自己的产出。
原则二:上下文管理不等于扩大窗口。 当前行业的热点是"模型能支持多少 token",好像上下文窗口越大一切问题就解决了。但 Webwright 告诉我们,更好的方法是让 Agent 学会在上下文中做"选择性遗忘"——不是忘掉信息,而是把信息压缩到最精华的结构。把 100 步的详细日志压缩成 5 句摘要,比硬塞进 10 万 token 的上下文要聪明得多。
这两个原则,放在最近出现的其他研究中也都成立。
Google DeepMind 的 AlphaProof Nexus 用"LLM 生成证明 → Lean 形式化验证 → 编译错误反馈 → 修正"的循环来解决数学问题。这里的 Lean 就扮演了"门控"角色——模型不能声称自己证明了定理,只有当 Lean 编译器说"通过了"才算数。
NVIDIA 发布的扩散语言模型 Nemotron-Labs 走了另一条路:通过架构层面的改变来"压缩"生成过程本身,而不是压缩上下文。方向不同,但对"效率优先"的追求是同样的逻辑。
1000 行的意义
Webwright 最反直觉的地方不是它的设计,而是它的体量。
当前 Agent 框架的普遍趋势是越做越重:多智能体编排、记忆系统、工具注册、权限控制、规划引擎、状态持久化……每一个功能听起来都不可或缺。但 Webwright 用 1000 行代码证明,对于"操控网页"这个具体场景,核心逻辑不需要那么复杂。
这引出一个更深的问题:Agent 领域正在经历和前端框架类似的膨胀周期——大家都在不断往上叠加抽象层,却忘了检查底层是否真的需要这些抽象。
Runner 150 行。需要多智能体吗?不需要。需要分层规划吗?不需要。你需要的是:把上下文给模型 → 模型返回 shell 命令 → 执行 → 把结果返回给模型。循环。下一个循环。
这就是网页 Agent 的核心循环。所有其他的东西都是附加的。
当然,1000 行的代价也是存在的。Webwright 不处理身份验证、不处理反爬机制、不处理多窗口管理、不处理严格的权限控制。它是一个"展示可能性"的参考实现,不是一个产品级框架。但它展示了一个重要的方向:在 Agent 设计上,应该先确定不可简化的核心循环,再考虑附加功能,而不是反过来。
为什么这很重要
Webwright 出现在这个时间点不是偶然的。
在当前 Agent 技术栈里,各个层面都在经历从"手工设计"到"自主行动"的转变。模型越来越强大,但 Agent 的可靠性却跟不上——这就像有了更强的引擎但没有更好的方向盘。Webwright 的两个技巧——尤其是门控自检——为 Agent 的"质量控制"提供了一条不需要新模型的路径。
另一个更大的背景是,Agent 工作负载正在重塑推理经济。SemiAnalysis 最近从 43.2 万个真实编码 Agent 请求中提取的数据显示,中位数输入 token 高达 9.6 万。这是因为在用户输入问题之前,Agent 已经处理了全书级别的上下文。在这样的背景下,Webwright 的历史压缩策略显得格外务实:与其让模型消化所有历史,不如让它学会提炼关键信息。
回到 Webwright 的 1000 行代码。它不是一个产品,它是一份宣言:"网页 Agent 可以更简单。" 有时候,1000 行正确的代码,比 10 万行包装更接近事物的本质。