AMD MI355X × MoRI 在推理 TCO 上赢了 B200 — LMSys 深度解读
LMSys 联合 AMD 公布 DeepSeek-R1 分布式推理基准结果:MI355X 通过 MoRI 量化通信、TBO 重叠、AITER GEMM 调优等全栈优化,实现 $0.169/百万 tokens,比 B200 TRT-LLM 低 5%,比 B200 SGLang 低 40%。

背景
2026 年 5 月 28 日,LMSys 博客发布了一篇重磅基准测试报告:AMD Instinct™ MI355X 在 DeepSeek-R1 分布式推理场景中,首次在 TCO 上实现了对 NVIDIA B200 的全面压制。
这不是 AMD 的一家之言。所有数据经过 InferenceX 验证——这是 SemiAnalysis 维护的开源持续基准测试平台,覆盖数百 GPU 配置,有实时仪表盘。换句话说,这是一份第三方可复现、可质疑、可追查的基准。
关键数字:在 129 tok/s/user 的交互式部署典型工况下:
- AMD MI355X(MoRI SGLang MTP):$0.169/百万 tokens,2,436 tok/s/GPU(24 张 GPU)
- NVIDIA B200(Dynamo TRT-LLM MTP):$0.178/百万 tokens,3,128 tok/s/GPU(28 张 GPU)
- NVIDIA B200(Dynamo SGLang MTP):$0.284/百万 tokens,1,945 tok/s/GPU(48 张 GPU)
MI355X 不仅比 B200 TRT-LLM 便宜 5%,比 B200 SGLang 便宜 40%,同时每 GPU 吞吐量是后者的 1.25 倍——在成本和性能两个维度同时胜出。
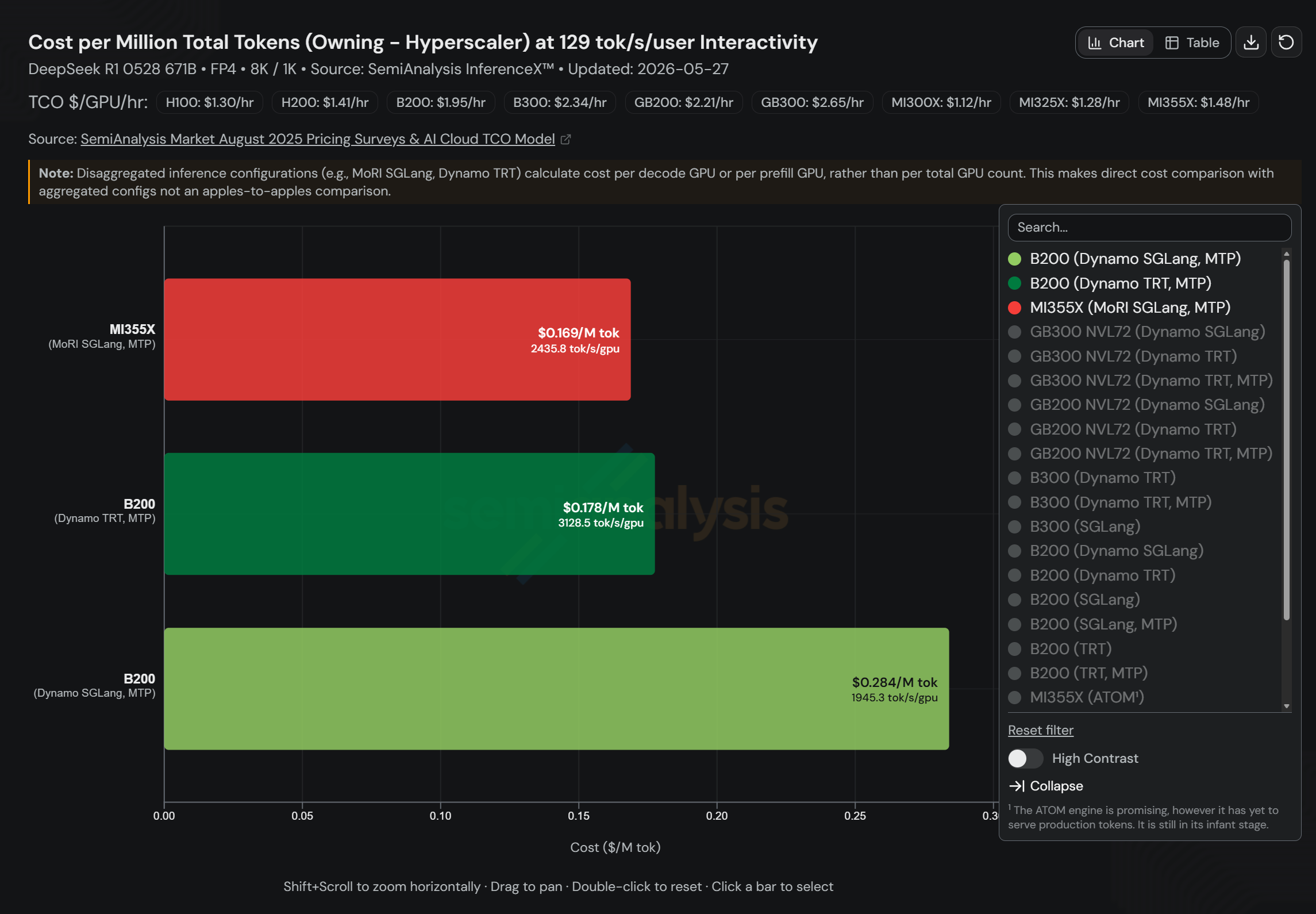
图 1:InferenceX TCO 对比——AMD MI355X MoRI SGLang vs B200 Dynamo SGLang vs B200 TRT-LLM。(完整 TCO 模型见 SemiAnalysis AI Cloud TCO Model)
帕累托曲线:全工况覆盖
单一数据点不能说明问题。InferenceX 的帕累托曲线显示了更完整的画面:
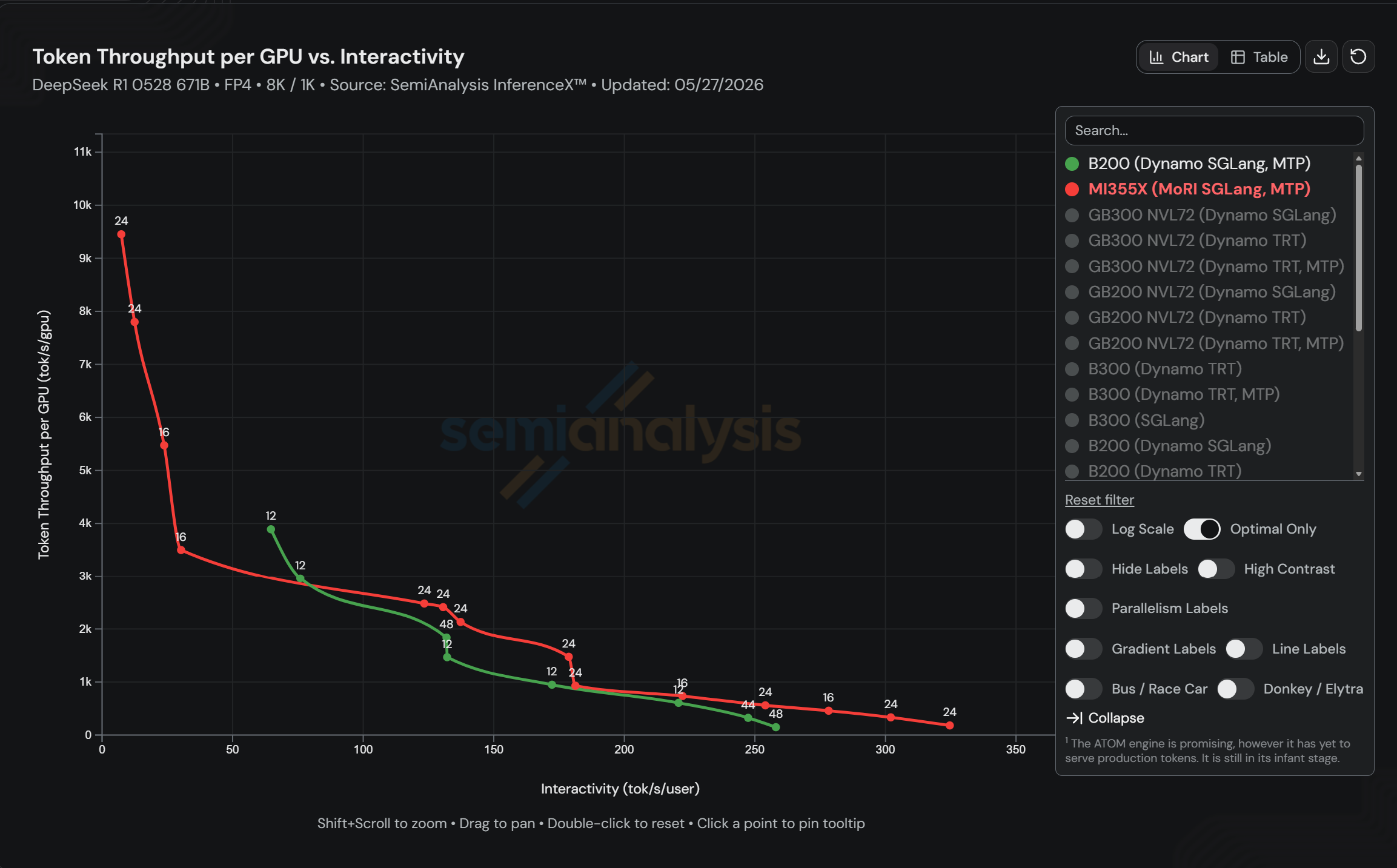
图 2:AMD MI355X 与 B200 各配置的全工况吞吐量 vs 交互性曲线
横轴交互性(tok/s/user)越低越偏批量处理,越高越偏实时。从曲线可以看出,MI355X 在大范围工况内都处于左下角(更低成本),在关键交互性区间(100-150 tok/s/user)更是显著领先。
为什么能赢?全栈优化拆解
这篇报告的真正价值不在于"AMD 赢了"这一结论,而在于 AMD 整合 SGLang + MoRI 所完成的整套全栈优化路径。这不是单一硬件或软件的优势,而是一个完整的系统工程成果。
1. MoRI 量化 All-to-All:通信带宽压缩 2.56 倍
在专家并行(Expert Parallelism)的 MoE 推理中,每个 token 都需要经过 dispatch(分发到 top-k 专家)和 combine(收集专家输出)两个通信原语。对于 DeepSeek-R1(隐藏维度 7,168,top-8 路由),BF16 的通信量巨大。
MoRI 的关键洞察:dispatch 阶段可以使用 MXFP4 量化且几乎零精度损失,combine 阶段可以容忍 FP8 量化。
AMD 团队在 SGLang 中实现了一套混合精度量化 all-to-all:
- FP4 dispatch + FP8 combine direct cast(PR #19757)
- FP8 blockwise combine(PR #24879)——细粒度 blockwise 量化,比直接 cast FP8 准确度提升 ~2%
- 自动检测 dispatch 精度(PR #21040)——无需手动配置环境变量
结果:MXFP4 模型上 2.56 倍往返带宽压缩(从每 token 28,672 字节降到 11,200 字节)。微基准测试显示,FP8 blockwise 的 combine 延迟约 736 µs,比 BF16 无量化基准的 907 µs 降低 19%。
2. 自适应内核选择
通信内核不是越多越好,而是在不同负载条件下选择最优内核。MoRI 实现了动态切换(PR #18437):
| 内核 | 条件 | 优化方向 |
|---|---|---|
IntraNode |
单节点(≤8 GPU) | 共享内存 / P2P |
InterNodeV1 |
多节点,>256 tokens/rank | 高吞吐,分段 RDMA |
InterNodeV1LL |
多节点,≤256 tokens/rank | 低延迟 |
AsyncLL |
SDMA 使能路径 | 全异步 send/recv 拆分 |
其中 InterNodeV1LL 在低 token 数场景下实现 1.52 倍 dispatch 和 1.82 倍 combine 加速——这对 decode 阶段尤为重要,因为此时每 rank 的 batch size 很小。
3. MoRI-IO KV Cache 后端:超越 Mooncake
KVCache 迁移是 PD 分离部署的核心效率瓶颈。MoRI-IO(PR #22665)做了三件事:
- Lock-free inline 传输:传输请求直接在内核调用路径中执行,而非调度到 worker 线程。传输计划预计算一次,所有层复用
- 高并发 RDMA:默认并行度提高到 4 个队列对 + 4 个传输 worker,线程安全的连接复用防止端口耗尽
- 更广的模型覆盖:支持 Mamba(SSM 状态)、SWA、NSA 等混合架构,以及 TP 不匹配场景(prefill 和 decode 使用不同的 tensor-parallel 度)
基准测试(8×MI355X 节点,8×AMD Pensando Pollara 400 AI-NIC,DeepSeek-R1 671B FP8):
| 指标 | MoRI-IO | Mooncake | 优势 |
|---|---|---|---|
| 请求吞吐量 | 7.49 req/s | 6.80 req/s | +10% |
| 输入 token 吞吐 | 31,111 tok/s | 28,257 tok/s | +10% |
| 输出 token 吞吐 | 3,775 tok/s | 3,428 tok/s | +10% |
| 总 token 吞吐 | 34,886 tok/s | 31,685 tok/s | +10% |
MoRI-IO 在所有指标上比 Mooncake 高约 10%,单请求延迟约 7 ms TPOT,GSM8K 5-shot 准确率 0.970。
4. Two-Batch Overlap(TBO)with SDMA:隐藏通信延迟
即使有了 2-4 倍带宽压缩,all-to-all 通信仍然是瓶颈。TBO 的核心思路很简单但高效:将通信和计算交错在两个微批次上。
流水线流程:
- 微批次 A 发送:量化后 token 经专用通信流发送
- 网络传输期间,微批次 B 注意力计算在计算流上执行
- 微批次 A 到达,MoE GEMM 执行
- 微批次 A combine 发送结果回通信流
- 同时,微批次 B dispatch 开始

图 3:Two-Batch Overlap 流水线——计算与通信交错执行
当启用 SDMA(MORI_ENABLE_SDMA=true),数据传输运行在 AMD 专用的 System DMA 引擎上,在 GPU 内存和网络接口之间移动数据时不消耗任何计算单元。这实现了真正的零计算开销通信。
三项 PR 的累积效果:大 batch 下吞吐提升 +25%,平均 TPOT 从 97 ms 降至 83 ms(-14%)。
5. FlyDSL FusedMoE:编译器驱动的内核优化
传统 AMD 上的 FusedMoE 依赖 Composable Kernel(CK)——手调模板,性能好但不够灵活。AITER 引入了 FlyDSL(Flexible Layout Python DSL),基于 MLIR 栈的 Python 内核 DSL,支持显式 layout 和 tiling 配置。
关键数据:在典型并发度 512 下,FlyDSL 实现 1.6 倍延迟降低。同时配合 Triton blockscale GEMM 调优,为 DeepSeek-R1 的专家维度(N=7168, K=16384 等)提供优化的 block size、warp count 和 pipeline stage 配置。
更重要的是,FlyDSL 正在集成 MoRI 的共享内存原语(PR #280),使得 FusedMoE 内核可以直接在同一内核中发出跨 GPU 数据传输——融合计算和通信为单次 launch,为未来的 warp 级重叠打开大门。
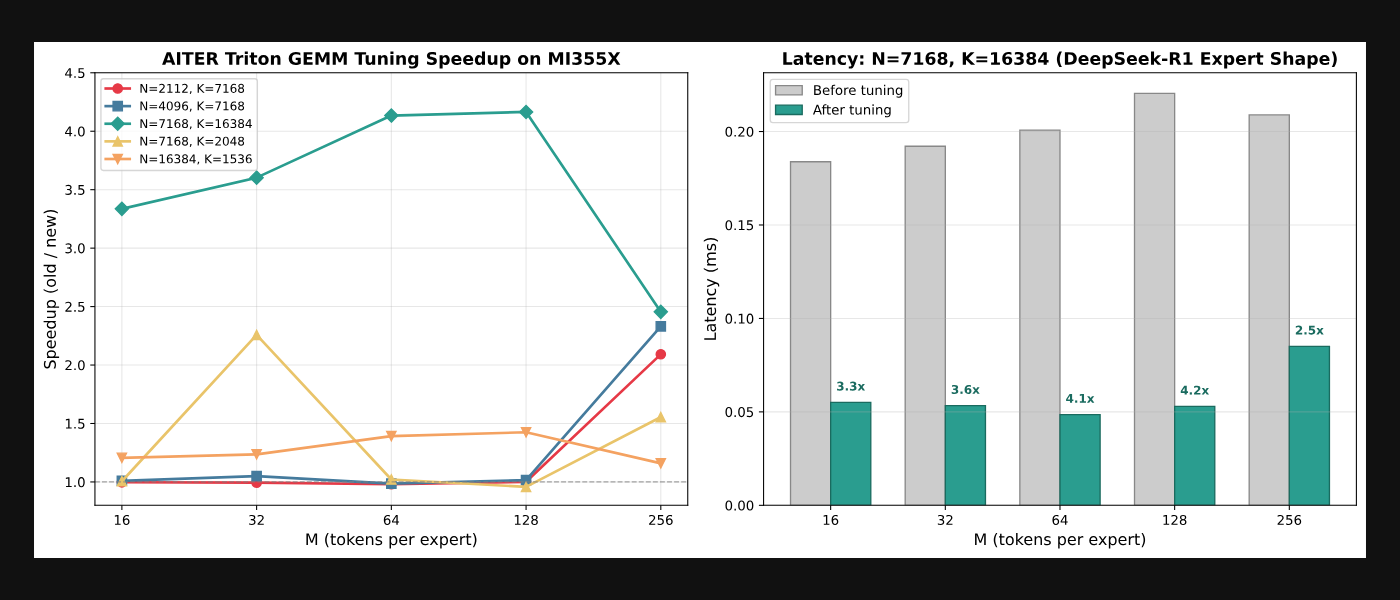
图 4:FlyDSL 内核和 Triton GEMM 调优加速效果
6. Specv2 MTP on ROCm
DeepSeek-R1 支持 Multi-Token Prediction(MTP),每次推测 3 个额外 token。SGLang 的 Specv2 流水线将 draft 和 verify 阶段在独立 GPU stream 上重叠运行,此前仅为 CUDA 支持。
AMD 团队在 PR #17450 中为 ROCm 添加了 AITER attention backend 支持,包括 draft 模型的 CUDA graph 捕获和 overlap plan stream。
综合效果:总 token 吞吐 +4%,TPOT -3.6%,无精度损失(GSM8K 5-shot: 0.923)。
MTP 还产生了一个有趣的复合效应:它将 decode batch size 提升了 4 倍(原始 + 3 个推测 token),从而改善了 all-to-all 通信的大 batch 带宽利用,同时 FP4/FP8 量化又保证了每个 token 的通信成本不因 batch 增大而爆炸。
7. CPU 流优化:当 GPU 不再是瓶颈
在高并发 PD 分离部署中(如 2,048 并发请求),GPU 流水线已经不是瓶颈——decode 侧的 CPU 路径成了限制因素。
PR #22658 做了两件事:
- 批量化通知:将 asyncio 事件唤醒从每请求触发改为分组触发
- SSE 快路径:在流式输出热点上,用直接
orjson.dumps()替代 Pydantic 序列化
结果:高并发下 输出吞吐 +20%,TPOT -16%。
AMD MI355X 的硬件成本优势
以上软件优化产生了重大收益,但硬件基座同样关键。根据 SemiAnalysis 的数据,MI355X 的部署成本为 $1.48/h/GPU,B200 则需要 $1.95/h/GPU——差距约 24%。
这意味着,同样的软件优化在 MI355X 上放大后,每 token 的摊销成本更低。这是 MI355X 能在 TCO 上反超 B200 TRT-LLM 的底层逻辑。
前瞻:从 Chat 到 Agent 推理
报告最后点出了一个重要方向:分布式推理的下一个前沿正在从聊天式工作负载转向 Agent 应用——Claude Code、Codex、Cursor 等工具驱动的深度多轮对话,伴随超长上下文(高达 100 万 token)、极高的 KVCache 复用率和并行子 agent 的快速请求爆发。
InferenceX 正在开发一个 Agentic Coding 基准测试来捕捉这些模式。AMD 将在这个工作负载上进一步优化,利用 DWDP(Disaggregated Wide Data Parallelism)和 SDMA 的全异步能力,匹配 Agent 推理的突发流量和缓存密集需求。
此外,SDMA 的零计算开销通信能力不仅限于推理——在 DeepSpeed 训练框架中的早期验证已显示 ~10% 的性能提升,意味着 AMD 的 DMA 引擎路线同样可能在分布式训练中产生竞争力。
总结
这篇 LMSys 博客的意义远超一个基准测试报告。它标志着:
-
AMD Instinct MI355X 在大规模推理部署中首次在 TCO 上具备与 NVIDIA B200 正面竞争的能力——不是小胜,而是 5% 比 B200 TRT-LLM 低、40% 比 B200 SGLang 低
-
全栈优化的力量:这份成果不是靠单一硬件或单一软件突破取得的,而是通信(MoRI 量化 all-to-all)、计算(FlyDSL FusedMoE)、服务器(TBO + MTP + CPU 优化)三位一体的系统工程
-
开源生态正在改变竞争格局:SGLang 和 MoRI 都是开源项目,InferenceX 也是开源的。这意味着任何团队都可以复现这些结果、验证这些数字、在此基础上继续优化——这比任何营销宣传都有说服力
-
Agent 推理时代 AMD 有机会建立壁垒:超长上下文、SDMA 零开销通信、DWDP 架构——这些能力在聊天场景或许只是"锦上添花",但在 Agent 推理场景下,可能是决定部署成本的胜负手
所有优化已合入 SGLang 主干,可通过 nightly ROCm 镜像 lmsysorg/sglang-rocm:v0.5.10.post1-rocm720-mi35x-20260501 复现。
数据来源:全量基准数据和复现方法见 InferenceX GitHub 和 实时仪表盘