Glean:当搜索做够七年,AI 时代才来
Glean 用七年时间从企业搜索走到 AI Coworker,ARR 15 个月翻三倍到 $300M。核心壁垒 Context Graph 五层架构让巨头们追不上。
2019 年,几位前 Google 搜索工程师创办了一家公司,做企业搜索。
这个选择在当时谈不上性感。企业搜索是一个老赛道——Google 自己就有 Google Search Appliance,Microsoft 有 SharePoint Search,创业公司里还有 Algolia、Elastic 这些玩家。而且企业在搜索上的付费意愿一直不高,大多数人觉得"能搜到就行"。
Arvind Jain 和团队没有被这个判断劝退。他在 Google 做了多年搜索,后来联合创办了 Rubrik(数据管理公司,估值超 40 亿),对"企业内部信息找不着"的痛苦有切身体会。
前四年没什么像样的竞争。CEO 自己的话说:"我们成立的头四五年,没有竞争对手。"
然后风向变了。2023 年大语言模型爆发,所有人突然意识到——企业里那些散落在文档、聊天记录、代码仓库、CRM 里的信息,不仅是用来"搜"的,还可以被 AI "用"起来。
Google 冲进来了。Microsoft 冲进来了。OpenAI 冲进来了。Anthropic 冲进来了。Salesforce 和 Atlassian 也冲进来了。
Glean 的反应很有意思——不是收缩防守,而是加速冲刺。
2024 年 12 月,Glean 达到 1 亿美元 ARR。2025 年 12 月,达到 2 亿美元。2026 年 5 月,达到 3 亿美元。15 个月翻了三倍。估值从 2022 年的 10 亿一路涨到 2025 年的 72 亿。投资方名单覆盖了 Sequoia、Kleiner Perkins、Lightspeed、Altimeter、SoftBank、DST Global 几乎所有一线基金。
"每个人都在做搜索,但 Glean 的优势不是搜索技术本身——而是它对企业上下文的理解深度。"
Context Graph:不是知识图谱
Glean 的核心技术叫 Context Graph。
知识图谱在业界已经是一个被用滥的词。大多数知识图谱做的是"实体—关系"建模——把客户、工单、文档、人标出来,连上线。Glean 的 Context Graph 不一样——它建模的是"变化"。
谁在什么时候、在哪个系统里、做了什么操作,这些操作之间的因果关系是什么。一个 P1 事故从创建到解决通常经过哪些步骤?从"创建商机"到"签单"之间最常见的路径是什么?
这些信息无法通过传统的知识图谱来表达。它们需要把"动作"本身作为一等公民,追踪动作之间的时序和因果链条。
Glean 用五层架构来构建这个能力:
第一层,连接器——深度集成 100+ 企业应用,不仅是爬文档,而是理解每个应用的数据模型和权限体系。
第二层,统一知识图谱——把不同系统的数据归一化为三元组结构,实体消歧("Reddit"是客户名称还是营销渠道?),细粒度权限控制。
第三层,个人图谱——理解每个用户的角色、项目、工作模式,不是基于聊天历史,而是基于他们在企业系统中的实际行为。
第四层,Context Graph——把动作作为一等节点,用因果边连接工作序列。
第五层,Agentic 学习反馈——Agent 执行后的动作轨迹成为新的图谱输入,强化学习评估最优路径。
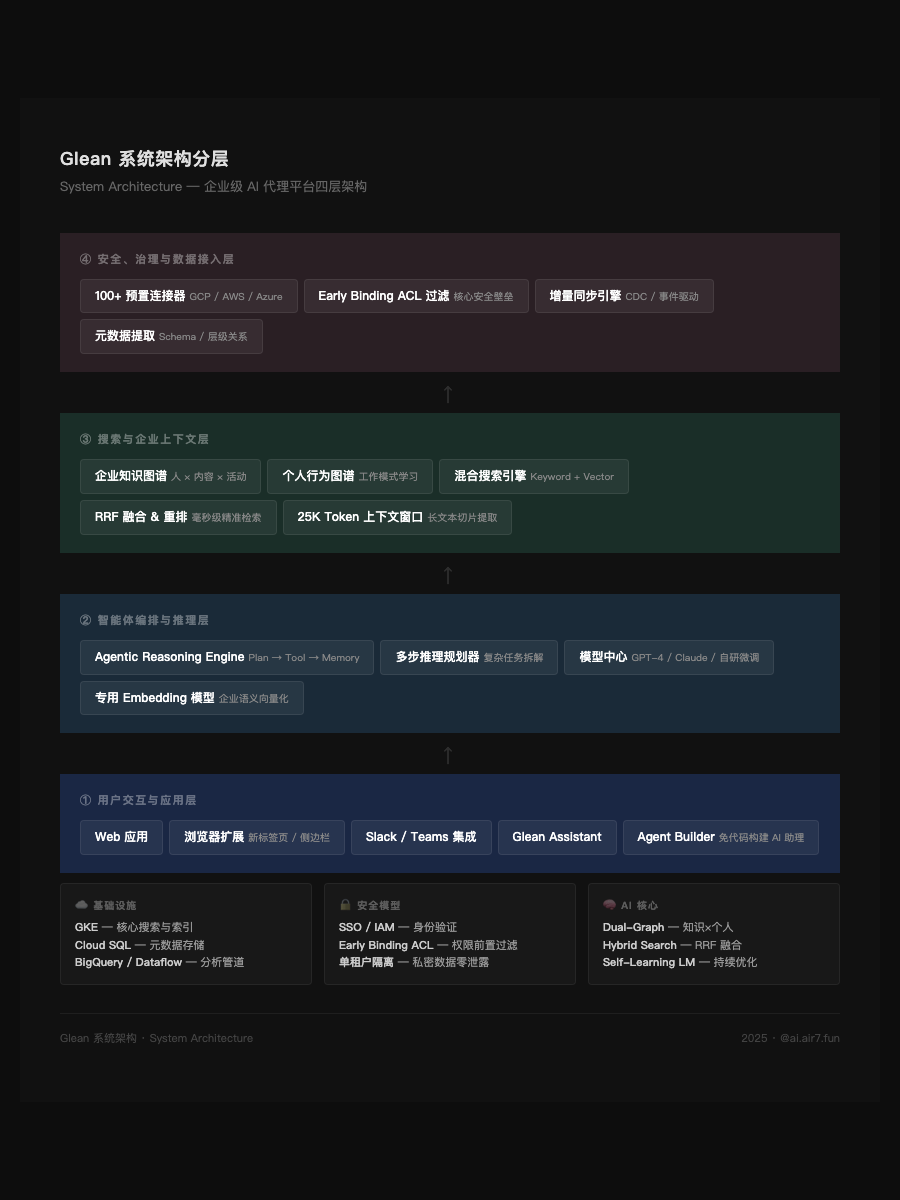
图 1:Glean 系统架构分层——四层架构:安全与数据接入层 → 搜索与上下文层 → 智能体编排与推理层 → 用户交互与应用层
这个五层架构的投入很重。但它建立了一个对手很难复制的壁垒——你需要先连接企业里所有的系统、理解所有的权限模型、积累足够多的行为数据,才能开始训练这个图谱。
Glean 用七年时间做了这件事。
核心数据流
在系统设计层面,当一个用户向 Glean 发出请求时,其内部数据处理管道清晰划分为六个步骤:身份验证 → ACL 前置过滤 → 智能推理与查询重写 → 企业图谱与混合检索 → RRF 融合与重排 → 模型推理与安全回答生成。
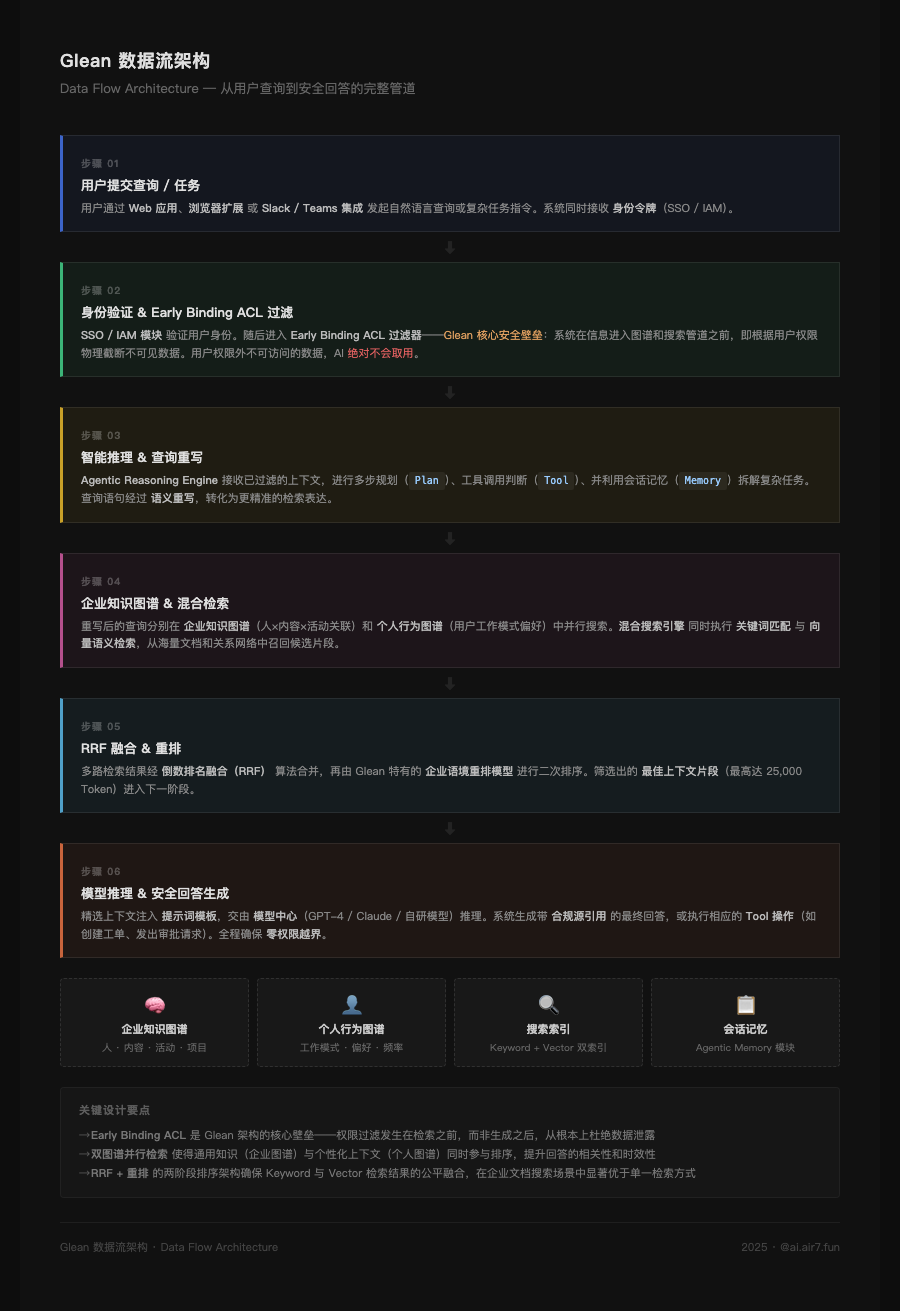
图 2:Glean 数据流架构——从用户查询到安全回答的完整六步管道,Early Binding ACL 在检索之前即完成权限过滤
云原生部署架构
在基础设施层面,Glean 深度依赖 GCP(同时也支持 AWS 和 Azure),采用三层隔离部署模型:企业客户侧网络 → GCP 单租户云环境 → 用户接入层。

图 3:Glean 部署架构——基于 GCP 的三层隔离部署,支持 Private Link 和 Bastion Host 两种数据接入方式
为什么竞争对手追不上
当 Google、Microsoft、OpenAI 们杀入这个赛道时,它们选择的路径大多是"联邦搜索"——通过 MCP(Model Context Protocol)或 API 网关,让 AI Agent 每次查询时实时去各个系统抓数据。
Glean 走的是相反的路径——集中式索引。先建立统一的索引,把企业所有系统的数据提前处理好,然后 AI 在这个索引上查询。
各有优劣。联邦搜索部署快——不需要提前集成,插上 MCP 就能用。但每次查询需要在多个系统之间来回调用,每个系统都要重新做认证、权限判断、结果排序。Glean 在一次内部对照测试中发现,用标准 MCP 工具比用 Glean 的集中式索引多消耗约 30% 的 token。用户选择 Glean 的频率是 MCP 工具的 2.5 倍。
在 AI 预算成为企业 CFO 关注焦点的 2026 年,"帮你省钱"变成了一个意外的核心卖点。
"如果你把 AI 直接连接到你的系统,它会消耗大量 token 去理解你的数据。如果你先把 AI 连接到 Glean,Glean 已经把上下文准备好了,AI 只需要做最少的操作就能拿到需要的答案。"
这不是理论——Glean CEO Arvind Jain 在 TechCrunch 采访中明确说,客户选择 Glean 的重要原因之一就是它能显著降低 AI 账单。
从搜索到 Coworker
Glean 的产品演进经历了四个阶段,每个阶段的跨越都不小。
第一阶段(2019-2022),企业搜索。统一搜索 100+ SaaS 应用,个性化、权限感知。
第二阶段(2023-2024),AI Assistant。2023 年 6 月推出 Glean Chat,用 LLM 做企业数据问答。支持多模型(GPT、Claude、Gemini),RAG 架构,带来源引用。
第三阶段(2025),Agent 平台。2025 年 2 月推出 Glean Agents——无代码构建、编排、治理上千个 Agent。Agent Builder 支持自然语言定义流程,按步骤选择模型,分支和循环逻辑。全年 Agent 执行次数超过 1 亿次。
第四阶段(2026),AI Coworker。系统开始主动工作——在你还未提问时就推送待办卡片,自动执行多线程任务,通过 Skills 系统把隐性的企业知识变成可复用的执行单元。
从"你搜它答"到"它帮你干",这个转变的核心是 Context Graph 在过去七年积累的数据资产。
几个具体的客户案例说明这个转变的深度:
Booking.com 用 Glean Agent 分析用户研究数据——过去需要分析师花几天从不同报告中手动提取信息,现在 Agent 在几秒内完成跨报告、跨市场的洞察提取。
Miro 用 Glean 做个性化销售邮件生成,团队在邮件撰写上节省了 80% 的时间。关键在于 Glean 了解每个客户的背景——过去的沟通记录、产品使用情况、行业动向——不需要销售代表手动查找这些信息。
Deutsche Telekom 在 8 万员工中部署了企业 concierge Agent,员工用自然语言处理 IT 和 HR 请求。Agent 不需要了解每个部门的工作流——它从 Context Graph 中学习"通常怎么处理这类请求"。
Reddit 用 Glean Agent 做安全威胁建模——将一个安全模型从构建到交付的时间缩减了 97%。
一个被低估的壁垒
Glean 面临的最大风险不是来自竞争对手的产品能力,而是来自平台绑定。
Microsoft 365 Copilot 可以免费捆绑到企业现有的 Microsoft 订阅中。Google 可以把它内嵌到 Workspace 里。OpenAI 可以用 ChatGPT Enterprise 的规模优势压低价格。
但 Glean 有一个这些平台都没有的东西——它和任何一个模型、任何一个云、任何一个企业应用都没有绑定关系。Model Hub 支持所有主流模型,Agent 平台支持 MCP、LangChain、AGNTCY 等所有主流协议。
这个"中立性"在 AI 基础设施快速演变的阶段是一个被低估的竞争优势。企业不想被锁定在某一个模型上——今天的 Claude 比 GPT 好,明天 Gemini 可能会反超。Glean 的架构让企业可以在不改变底层基础设施的前提下切换模型。
至于平台巨头的免费捆绑——Glean 的客户故事给出了一个相反的信号:Deutsche Telekom 有 8 万员工,Miro 是高速增长的 SaaS 公司,Booking.com 是全球最大的旅游平台之一。这些公司都有能力使用 Microsoft 或 Google 的原生方案,但它们选择了 Glean。
原因可能很简单:Copilot 只能搜到 Microsoft 生态里的数据。而一个现代企业需要连接的远不止 Office 文档和 Outlook 邮件。
回看这七年
Glean 的故事里最反直觉的部分是它前四五年"没有竞争对手"的时期。
在那个阶段,企业搜索不是一个热门赛道。大模型还没有爆发,"企业 AI"这个概念甚至不存在。Glean 在做的事——连接 100 多个企业应用、建立统一的权限感知索引、构建知识图谱——听起来像是一个吃力不讨好的基础设施工程。
但在 LLM 突然变得有用的那一天,这些基础设施直接变成了护城河。
因为当你的 AI 需要了解一个企业的运作方式时,你需要的不是一个 API 接口,而是过去几年里所有系统、所有权限、所有行为数据的完整映射。这个东西不可能在几个月内建好。
Glean 的故事对今天的 AI 创业者可能有一个隐喻:不是所有机会都在浪潮最高点。有时候你在低潮期投入的笨功夫,会在下一个浪潮来临时变成别人过不来的墙。
Glean 的客户名单上已经有 Databricks、Reddit、Pinterest、Samsung、Booking.com、Deutsche Telekom。它的估值在七年内从零增长到 72 亿美元。它面对的是 Google、Microsoft、OpenAI 三个有史以来最强大的科技公司同时在一个赛道里竞争。
但增长没有放缓,反而在加速。
有时候,做一个不够性感的赛道,就是把竞争对手晾在起跑线上的最好策略。
因为当你们终于准备出发时,你已经跑了七年。